Abstract
The digital reproduction of texts, maps, still images,
moving images and sound brings about a profound revolution in
how we relate to cultural artefacts past and present. What
was separated by time and in completely different media and
realms, becomes reduced to bits and bytes and travels side by
side in fiberoptic networks around the globe, made available
to us immediately as we request it. This profoundly not only
changes the cultural artefact itself, but also the way we
relate to it.
In this paper, I will discuss some of the implications this
has, but I will focus on the technical side of this
development. Also, instead of discussing new media in general,
I will account only for textual material, not for visual or
acoustic forms, except in a very general sense. In the process of digitization, there are
important considerations to be made that have not been
required before. While digitization seems to be a simple and
straightforward technical process, it actually relies heavily
on the interpretation of the source material. This has to be
based on thorough consideration and should be done carefully
and informed.
Digitization can take place on several different levels and
the level to choose depends on its intended use. I will focus
my attention on the digitization of text and will use the
digitization of the Chinese Buddhist Tripitaka as an example.
The questions I will try to answer are the following: What
is the process of digitization? What assumptions are implied
by digitization? What kind of different levels do exist and
how do they relate to each other?
It will be important to take these questions and there
answers into consideration when dealing with digital media,
since there are a number of decisions to be made. Digital
media by itself have no a priori architecture, it is our
interpretations that call this architectures into existence.
For this reason, it is important to make these interpretations
explicit and arrive at informed decisions, since this will
very directly influence the usefulness of digital texts.
Contents
1. Introduction
In 19351, Walter Benjamin wrote his famous essay
Das Kunstwerk im Zeitalter seiner
technischen Reproduzierbarkeit2 [The
Work of Art in the Age of Mechanical
Reproduction3], which was later to be reproduced
endlessly to become a classical theoretical piece in an easily
digestible form. In this essay, he argues that the originality of the work
of art is lost when it is reproduced with the means of
technology, since its specific `aura' can
not be reproduced and is only perceivable in the presence of
the work of art. But even without this
`aura', the new presence of the artwork in
places where it did not penetrate before, is an important
achievement that makes it accessible to masses as never
before:
‘The cathedral leaves its locale to be received in
the studio of a lover of art; the choral production, performed
in an auditorium or in the open air, resounds in the drawing
room.’
Unfortunately, not only in the drawing room, but
also in the supermarket, airport and commercials: It has
become an integral part of modern life and completely changed
its character. If we want to experience the original aura
however, we still need to go back to the place where the
cathedral stands or where a performance is taking place.
In this paper, I would like to offer my own perspective on
reproduction through means of technology, not of works of art in general,
but of texts, which unfold and reach its audience in a much
different way than the works of art analyzed by Benjamin. I
am also not concerned with the
`technical' reproduction in general, but
only with its digital form, which can also be seen as a subset
of Benjamins topic. My aim is to provide a theoretical
framework to understand the working of digital texts, but I am
not going to explore its implications for a larger aesthetical and political
framework; I will be much more concerned with the technical
side here. In a way, this can be seen as some kind of footnote to Benjamins
essay, since the original work of art is
completely out of scope for my discussion here, I am concerned
only with its digital representations.
2. A general model of Digitization
In order to lay a foundation for this discussion, it seems
to be necessary to device a processing model for digital
works. This should be general enough to be applicable to all forms
of digital content, but is specifically intended to be applicable
to text.
2.1. First try: A simple model for digital
processing
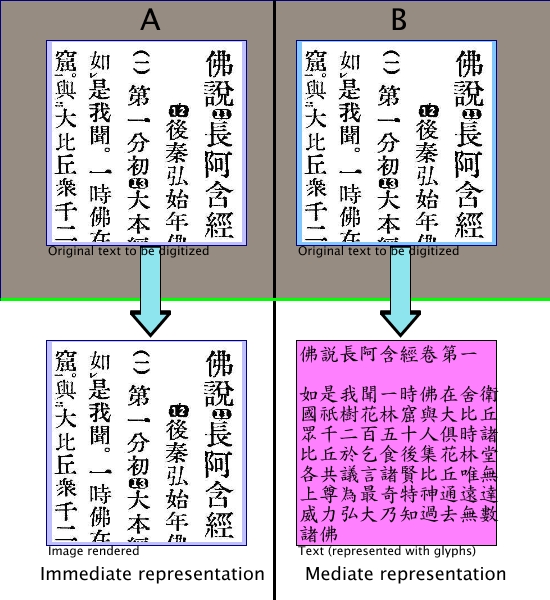
Figure 1
A simple model for digital
processing
In this model, the `original', which is
itself outside of the digital world (indicated in the upper
part of the model with a darker background), is represented in digital
form by two kinds of representations: The first type, which in
Figure 1 is labelled with A is what
I will call an `immediate' representation,
it is immediate in the sense that the transformation to the
digital medium `only' involves a
transformation but not an interpretation. A second type of
digital representation is labelled B and is called a
`mediate' representation, since it is
arrived at through an act of interpretation, either of a
digital form of type A or
directly of the original outside the digital medium.
To make the differences of these types clearer, I will list
some examples in the following table:
Table 1: Some common formats for the two types of
digital representation
| Type of medium |
Immediate representation |
Mediate representation |
| acoustical |
WAV |
MIDI |
| visual |
BMP, TIFF, JPG, FAX |
EPS, SVG |
| textual |
BMP, TIFF, JPG, FAX |
TXT |
| audio-visual |
AVI, MPEG |
?? |
In this table, the textual form shares the same immediate
formats with the graphical forms, which underlines the fact
that as far as digital media are concerned, a text in
immediate representation is just another graphical entity and
none of the handling that is available for text can be applied
to this form. It is also interesting to note that, although
it might seem that the mediate textual representation is
somehow derived from the immediate presentation form, it
was the first and for some time primary form of textual
representation in the digital medium. The reason is not
difficult to discern: The textual representation could almost
be called the native language of a computer, since this can be
easily reformulated as symbolic manipulation, which is at the
heart of all computer based operations. This
is especially true for text generated directly in an
electronic medium, through typing on a keyboard or some
similar mechanism, as is the case with this paper.
In order to fully represent digital operations in this
model, however, it needs a little refinement. Strictly
speaking, none of these digital formats can be directly
encountered, all of them need an application that renders them
in a comprehensible way. Any digital format is just a string
of bits that ultimately can be reduced to 0 and 1. The
expected rendering of the contents of the format depends on
the correct interpretation of these bits. Depending on the
type of the content, this can very well involve a number of
different steps. In order to simplify the discussion, I will
concern myself only with graphical formats, including text.
2.2. Second try: A modified model of digital processing
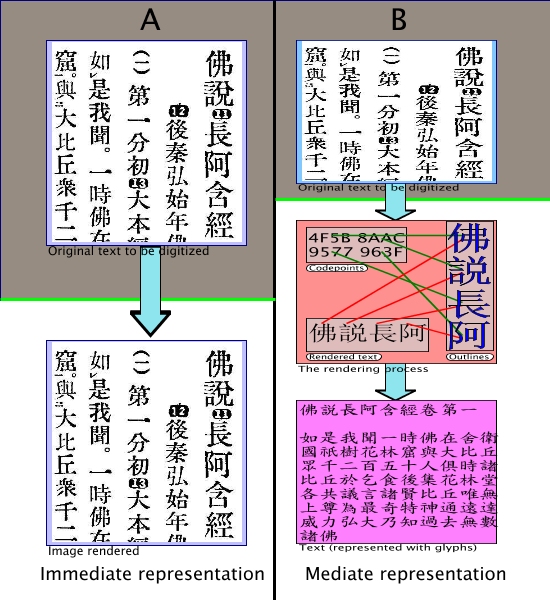
Figure 2
A modified model of digital processing
In
Figure 2 the model has been modified
to include the steps of rendering of a data format. As can be
seen, for the immediate format, the rendering depends only on
the information stored in the data file, from which the visual
representation can be directly derived. For the mediate
representation, however, an additional step is required, that
retrieves graphical representation of the units that are
stored in the file, but the information of the visual
representation itself is not stored. From this can than a visual
representation be constructed, but this representation has a
much loser connection to the contents of the data file, it is
just one of a number of representations, whereas an immediate
digital form has only one correct rendering (all other
renderings would misinterpret the bytes in the file and
produce only garbage).
It should also be noted, although this will become clearer
later, that in the digital medium the work of art is not
directly encountered, it has always to be
interpreted by an application. In contrast to the
uniqueness of the work of art that Benjamin describes and
that, according to him is lost through reproduction, there
is not only no uniqueness in the digital medium, but not
even a unique form: the digital work of art exists only in
a symbiosis of the content, the application (which might be
divided in many cases in an application program and the
underlying operating system), the computer hardware and the
user. To put it another way around, in the digital work is
a unique combination of software and hardware, so much so
that is is hard to find two digital works that are identical.
2.3. Finally: A model of digital processing
For completeness, yet another step has to be introduced,
which leads from the textual representation to the display
of characters, which gives more control over the process of
how the rendering is done.
In the previous model, no selection of a specific
typeface, style, point size or colour was possible, also
there was no way to control the positioning of the text on the
page. Of course, all these dimensions did get a specific
value, which simply was some kind of built-in value that
some programmer decided when writing the program that
displays the text.
To make this more explicit, we need to integrate this
kind of information into our model, which looks now as in
Figure 3. This image shows only the middle
right part of the model in Figure 2, since this
is the only part that has been modified. What is labelled
`Selection of text attributes' is where the information
about how to display a certain character is processed.
Based on this information, the system looks for suitable
font files, selects the appropriate glyph in these fonts,
renders it in the desired size, colour and style and then
displays it.

Figure 3
A portion of the model showing how text
attributes are assigned
With this model in place, it is now time to look at some
of the processes in more detail. The next section will
discuss how characters as they exist in the world outside of
digital media are encoded into digital form. This will be
followed by a discussion of what was called
`rendering process' here, but actually
covers much more, depending from which angle one looks at it.
While the model in Figure 3 is complete as
far as visual representation is concerned, there is another
aspect of electronic texts that is not yet sufficiently
represented, this is the `information
content'. To accomodate for the proper treatment
of information content, the model has to be refined once
again, which will be done below, after discussing some of
the aspects of the visual appearance in more detail.
3. From letters to characters
To understand how characters are processed in digital
media, it might be useful to first consider the process of
digitization itself.
3.1. The process of digitization
Digitization is the process of making something available
in digital form. In this digital medium, everything is
expressed by assigning numeric values. The range of
possible values and the intervals by which these values are
assigned, allow finegrained control over the result of
digitization. The process of digitization is thus governed
by the two parameters of `range of possible values' and the
`Sampling frequency'4.
To illustrate this point, I have created
three different images of a Kanji character as shown in
Figure 4. These are grayscale images, all of them have the
same range of possible gray ranges, but the
`resolution', which in this case
is the number of pixels used to construct a character, is
different: the first one has 24 pixels per character, the second
one 32 and the last one 48. They are here shown all scaled to the
same size to make it easy to compare them.

Figure 4
The same character in different resolutions
As can be easily seen, the higher the resolution, the more of
the details of the shape of the character can be captured,
while the characters with the lowest resolution are difficult
to recognize, especially since they are scaled up.
While it is possible to increase the resolution to capture
more of the features of the graphical representation of
images, or in this case, characters, this is neither efficient
nor practical, since the optimal resolution would depend on
the resolution of the device used to view the digital image,
which can not be determined at the time of digitization and
which can vary dramatically. Of course it is also possible to
increase the range of possible values, for example to be able
to capture colors and not just greyscale values as in the
example of Figure 4, which will also result in increased
fidelity of the digital image.
3.2. Representation of character shapes
Within the framework of pixels and values, the dilemma
posed here cannot be solved. However, digitization can be
based on any other framework as well. Figure 5 shows the
character expressed as a filled outline.

Figure 5
A character with the defining points of the
outline marked in red and green
The outline is
described with mathematical functions, known as Bézier
curves5. Instead of directly
describing the character as a series of points that are either
black or white, the desired shape is described by giving
reference points where necessary and then describe the way
these points are connected. With this method, a character
form can be described independently of the actual point size
it is later rendered at and it can be scaled without producing
unwanted
This operates
on a much higher level, which can than be used to calculate the
individual values for a given resolution at the time a character needs to
be shown. The advantage of this abstraction is its higher
efficiency and greater flexibility. However, since there is a
process of abstraction involved in going from the concrete
shapes of a character to its idealized mathematical
description, this also means that some details do get lost.
In this case however, this does not matter, on the contrary,
what is desired here is the ideal shape, not one single concrete real
shape.
3.3. The character / glyph model
As outlined above, the digitization process from
individual formed letters or characters to digital
representations involves a process of abstraction. This
abstraction allows to group characters or letters of very
similar shape together and represent them with the same
character. There are however cases where even small
differences in the shape of a character constitute a
semantic difference that requires representation with its
own entity. To account for these facts in all its
complexity, a model had to be developped, which allows the
handling of glyphs and represent them by characters, this
has been called the `Character / Glyph
model'.
Before discussing this model further, it might be useful
to clearify the terminology used. Glyphs are the actual shapes
as they can be seen on paper or any other medium that allows
visual representation. Characters on the other hand are
abstract entities based on their semantic value, these
abstract entities can be visually represented with glyphs.
Usually there is an unlimited range of glyphs that can
represent one given character; glyphs can be seen as
instantiations of a character that is itself not
representable. Characters are identified and distinguished from each other
by their semantic value6.
Digital encoding of text operates on characters, not on
glyphs. This implies that the glyphs as they appear on
paper have to undergo a process of abstraction to find the
adequate character that has the desired attributes and thus
can be used to represent the glyph. It is very important to
note, that the selection of the appropriate
character to be used is not only based on its form. There
might be two or more similar glyphs available that are used
to represent different characters, they have to be
distinguished based on their other attributes and selected
appropriately. 7.
This is a second layer of abstraction, which operates on
a different layer than the abstraction mentioned above in
the discussion of Figure 5. The
abstraction there went from individual pixels to outlines,
here we go from indivdidual glyphs to classes of glyphs,
which can be seen as instantiations of characters.
4. The rendering process
With the character / glyph model in place, we can now look
back to Figure 3 and try to understand the
process of rendering more thoroughly. The characters have
been assigned numerical values according to some
`Coded Character Set', which in this case
is The Unicode Standard. All information about
exactly how a character looked previous to its digitization is
now completely lost, all that is left is a simple number
representing the character. In the model of Figure 3 for example, the character for
`Buddha', 佛 has the numerical value 4F5B,
説 corresponds to 8AAC and so forth.
This method is fine and very efficient for data
transmission and storage, but at some point the text needs to
be shown to a reader again and will need some visual
representation. For this purpose, a glyph has to be chosen
from a font to render the character indicated by the codepoint
on some display device. In some cases, for example on
terminals or simple line printers, there is virtual no control
on the rendering process, since only built in defaults are
used. In the more general and also more frequent case, some
control can be exercised over how the character is to be
displayed: The font family8, font size, style and other attributes
can be selected in many cases, but the exact mechanism to do
so depends on the application used.
This selection of text attributes is represented by the
central box in Figure 3. The lines in green with
long dashes are representing the process from the codepoint
through the selection to the selection of corresponding
outlines of a font file, which is represented in the vertical
box on the right hand side of Figure 3. From
the selected outlines there are lines in red with short
dashes, representing the process of rendering and laying out
the desired glyphs according to the desired values.
While many word processing software implements ways to
assign such a layout to text, it is clearly desirable to have
an open and application independent way of doing so. One
commonly used method is applying `markup'
to the text, i.e embed the information into the text itself.
Over the past decades, a number of markup languages have been
developped, according to quite different models. Some of them
assign text attributes directly to parts of the text, while
others introduce another level of abstraction by naming parts
of the text and applying the text attributes through
application to these named parts. Markup vocabularies based
on SGML9 or
more recently XML 10 are designed to separate information
related to the semantic analysis (or the
`information content' of a text and its
visual representation. Details of this will be discussed in
the next secion.
5. Digitization as communication
So far, text has been only presented as a visual
object. While this is an important aspect, it is usually not
the most important one. The raison
d'être of a text is the message it has for the
reader. If the message is read and understood, there is
little that needs to be kept of the text. No model of text
processing could therefore be complete without taking this
important aspect into account.
5.1. Markup: A method to imbed information into digital text
A major difference of text on analog media and digital text
is the fact that the reader of a digital text is not only a
human being, but might as well a computer program. While it
certainly can not be said that computer programs to read,
understand and appreciate texts, they can be programmed to perform certain
actions triggered by features in a text. These rules might
then analyze, transform and rewrite the text in a special
purpose form for ultimate consumption by a user who
requested this action to take place.
Using this terminology, a search request for example good
be understood as a request to read all the target texts,
compose a new text consisting of excerpts from these texts
based on the occurrence of some search term provided by the
user.
Even the rendering process as outlined above can also be
understood in this terminology as a request to read the
text and rewrite it to the display based on certain rules.
The only difference here is that the rules will govern how
different parts of the texts are displayed.
It should be evident that all these and similar processes
would benefit enormously from a better understanding of a
text. For this reason, there are a number of possible
methods, but I will limit myself here to one example of
this, which is the use of SGML/XML based markup
vocabularies, specifically the one maintained by the TEI
Consortium. 11 The TEI markup vocabulary defines a large
set of elements, that can be used for general text markup,
but also analytic linguistic markup, markup for
dictionaries, transcriptions of spoken text and many other
text types past or present, in all languages of the world.
Figure 612 shows how this concept of markup fits
in the model of text processing. The section A and B of the
model, which where only concerned with the visual
representation, have now been supplemented with a section
labelled C, which describes a model for the
processing of the information content, in this case using
the TEI markup vocabulary and the CSS stylesheet language
developped by the World Wide Web Consortium.
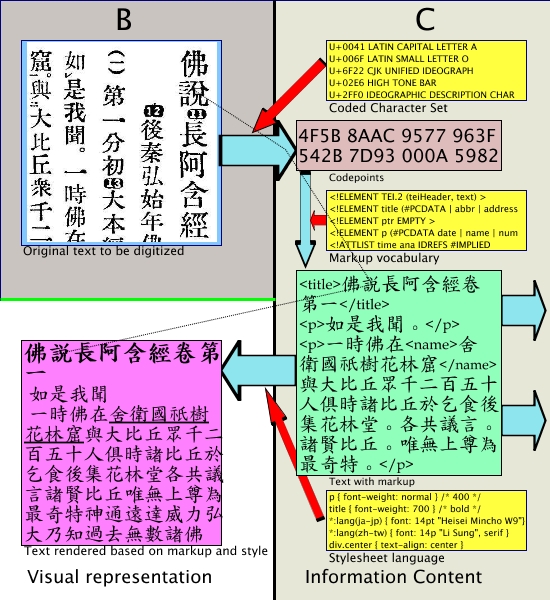
Figure 6
A model of digital text representation including
the information content
As can be seen in Figure 6, the markup
describes verbosely what function has been assigned to
portions of the text. The first few characters in this
example have been labelled with the element <title>,
which is some indication that the characters that are
contained between the start tag of this element
(<title>) and the end tag of this element
(</title>) have been considered a title by the person
who introduced this markup into the text. This information
can than be used while processing the text. While the
computer and the processing programs do not understand the
meaning of a <title> element, the name
`title' has been chosen by the developers
of the TEI markup vocabulary so that those human beings applying and
reading the markup can have some indication of the semantics
that are associated with this element13.
The information implanted into the text in this way can then
be used to render the text based on this information. In the
model of Figure 6, the text shown in the lower
part of section B has the title rendered in slightly larger
point size and with a bold face. Paragraphs (element
<p>) are indented slightly and the place name in the
first paragraph has been underlined to distinguish it from the
other text.
While this is an important achievement, it certainly is not
the only and also not the most important use of markup. More
importantly, text with sophisticated markup can be analyzed
with programs that make use of this markup to extract certain
portions,
5.2. Limits and shortcomings
While the methods described in this model are currently in use in
many places and can be seen as the most advanced methods for
representing digital texts, they are not without problems.
As has been shown above in the section The character / glyph model, in the
current model of digitization, the shapes of glyph instances
are discarded and replaced with codepoints. Therefore,
information about these shapes is not available by the time
the glyphs are to be rendered again. This process clearly
priviliges the information content over the visual
representation. This model works reasonable well for
alphabetic scripts, which inthemselves already implicitly
contain this abstraction. Other scripts, for example the
ideographic or logographic scripts of East Asia do not
embody this abstraction. Moreover, the culture itself
places a high importance on such differences, which are seen
as significant, even if they do not contribute to the
information content.
For this reason, the ongoing process of providing a Coded
Character Set for Han characters14 has not strictly
implemented this model, but rather accepted multiple glyphs
of the same character, which have been assigned different
codepoints. As can be seen, this process privileges the
visual content over the information content, which poses
severe challenges to the processing of the information content.
It should be obvious that it will be difficult to
accommodate both the visual representation and the
representation of the information content on the same
level. Both have to be accommodated, but they have to be
assigned to different layers in order to make both of them
accessible. The current model as shown in Section C of Figure 6
has to be modified accordingly. It will be necessary to
make it possible to preserve some of the information about
the glyphs used in the original text, that is currently
discarded on its way to the representation with
codepoints. In the model, this is represented with a dotted
line that branches out of the arrow connecting the original
text outside of the digital world (Section B, upper part
with dark background) with the codepoints representing the
information content. To give an example, the dotted line
extends actually from a character in the representation of
the original text through the markup representation to the
rendering in the lower part of Section B, showing how the
information about which glyph was used has been lost.
This information has to be placed into
the markup layer15
5.3. Future directions
It has been noted previously that the process of
assigning numerical values to characters and also the
process of assigning markup to portions of a text has to be
seen as an interpretation of a text. Currently, only one
interpretation is possible, thus clearly privileging a
specific view of a text while at the same time making other
views very difficult to hold. For most texts, the idea of
having only one possible interpretation seems to be
ridiculous, so clearly a way to accomodate conflicting
interpretations and process them productively is a big
desiderate and has to be taken account for future developments.
The process of digitization has been constructed as a
process of increasing abstraction from characters to
semantic units of texts. Visual and semantic properties
have been shown as conflicting parameters of the
construction of digital texts and will need further work to
be accomodated. The semantic analysis has however not yet
been applied to the lexical content of the text itself.
Integrating such a lexical database, which should also
contain the different graphical forms used for the
representation (or, in the case of alphabetical scripts,
different orthographical representations), together with
information about its usage, could go a long way of
mediating between these conflicting views of a text and on
the same way provide even better ways to access and analyze
the information content. This seems especially desirable
where, as is the case with Buddhist texts, the
analytic interests include not only literary or linguistic
aims, but most importantly those that are concerned with
what the texts have to say to their readers, thus
contributing to a better understanding of the rich textual
tradition of Buddhism.
6. Conclusions
In this paper, some attempts were made to develop a model
for the processing of text in digital form. With more and
more text transcribed and transformed into the digital medium,
it is important to analyze the potential and pitfalls of
current methods and seek for proper theoretical foundations.
The analysis presented here has been short and limited by
the dimensions of an academic paper. It has shown however,
that such an analysis is necessary and can uncover shortcomings
in even the most sophisticated of the way texts are currently
handled in digital form. To make informed use of the digital
medium and provide a long term means of the very basics of our
cultural traditions, it is necessary to further develop the
ways these shortcomings are handled to avoid irrecoverable
loss of information. While some directions have been shown,
further research and a refinement of the underlying model of
digitization is necessary to achieve this.
Notes
1. The initial essay was written in 1935, but was
rewritten in February of 1936. The second version was assumed
lost until its discovery in the Horkheimer Archive, published
in 1991. This second version, published 1936 in an edited and reduced form
in French was the only version that was published in Benjamins
lifetime. Benjamin continued to work on this essay, as
testified by letters and notes in 1938 and 1939. The
modifications include reformulations and new material, but
also drop some of the concepts of the second version. The
third version has become the standard version used in most
subsequent publications.
2. Reprinted in
Siegfried Unseld (ed) Illuminationen,
Frankfurt 1977, p.136-169.
3. In English available (as
translation of the third version by Harry Zohn) in Hannah
Arendt (ed.),Illuminations. Essays and
Reflections, Schocken Books, 1985, p. 217-252. It
should be noted that a literal translation of the title would
read The Artwork in the Age of its Technical
Reproducability. `Technical'
has a much wider connotation than the pure
`mechanical' and seems thus reflect
Benjamins intentions better. In a similar way,
`reproducability' points to Benjamins
concern not just with existing forms of mechanical
reproduction (photography, sound and film at his time), but
the impact the potential to be technically reproduced has on
all forms of art.
4. `sampling
frequency' is the general term, but since I will
be concerned mostly with spatial extensions, the more
concrete and familiar term is `resolution', which I will use
from now.
5. Named after the French engineer Pierre
Bézier (1910-1999), who worked for the French car company
Renault. He developed these curves in the late
1960's to represent a three-dimensional model of a car on
computers. Bézier curves now form the underlying technology
for all advanced font formats.
6. This includes a wide range of
attributes, including the writing system that a character
appears in, its name, the class its form is belonging to (upper or
lowercase, if casing applies at all). Additionally, a
character might be a representation of a numeric value,
might be a word constituent, if the writing system uses
words. For a good example of semantic values, see the
character properties database of The Unicode Standard
7. The character / glyph model as
represented here is slightly simplified. A full treatment
of the matter can be found in International
Organization for Standardization Information technology — An
operational model for characters and
glyphs (ISO 15285), 1998.
8. A font family is a not very
well standardized way to categorize fonts according to some
attributes, for example whether or not the include serifes.
This is based on western typography and has very little
relevance to the rendering of scripts other than alphabets
based on the Latin script. Unfortunately, so far there is no
established and well implemented procedure for any font
selection mechanism that goes beyond vendor specific naming
conventions.
9. The `Standard Generalized Markup
Language', originated in the 1960's at IBM and was later
further developped by the International Organization for
Standardization (ISO) and adopted in 1986 as ISO
8879:1986. One of the most widely used markup vocabularies
implemented as an application of SGML is the HTML (Hypertext
Markup Language) used in the World Wide Web.
10. XML, the
`Extensible Markup Language', is a modernized
version of SGML, developped with the stated intend of making it
easily usable over the Web, but in a much more flexible form
than HTML.
11. The Text Encoding Initiative, an international
cooperative project with more than hundred scholars from many
different disciplines of the Humanities, has successfully
compiled and published: The Association for Computers and the Humanities (ACH), The Association for Computational Linguistics (ACL) and The Association
for Literary and Linguistic Computing (ALLC) Guidelines for Electronic Text Encoding
and Interchange, edited by C. M. Sperberg-McQueen and Lou Burnard, TEI P3 Text Encoding Initiative Chicago, Oxford, May 16, 1994.. The project
has been recently
reorganized into a membership consortium and the guidelines
are currently under revision to bring them in line with some
technical developments, but the underlying intellectual model
has proved valid and does not require fundamental
changes.
12. To preserve space, the
leftmost portion of the model, which was labelled A has been left out, since there are no
differences to previous versions of the model.
13. This
naming scheme is of course biased towards English speakers,
but the TEI allows its elements to be renamed in other
languages, while the programs interpreting the markup still
recognize the elements and the associated semantics.
14. currently, with the
addition of more than 40000 characters in 2001, the total
number of assigned codepoints for Han characters exceeds
70000, but the process of preparing extensions to this
repertoire is still continuing.
15. Currently, the markup vocabulary
maintained by the TEI Consortium does not have a good
mechanism to accomodate this. Work is under way however, to
remedy this situation and make this or a similar model
actually usable.
Date: Time-stamp: "02/05/31 11:35:17 chris"
Author: Christian Wittern.