Author: Christian Wittern,
Taipei -- Created: 00-05-20, Last change: 00-06-28
URL of this document: http://www.chibs.edu.tw/~chris/smart/workbench.htm
Christian Wittern: Toward a Web-based Scholar’s Workbench
(邁往網路上的學者工作站)
Abstract
Today’s abundance of textual and other data at the disposition of scholars in fields such as Sinology allow for quick access to a wealth of resources that could never be dreamed of until only a few years ago. Yet, to the frustration of anybody who has started working with data on the Internet, there is much to be desired, to make websites truly useful scholarly resources. Aside from technical issues, questions of reliability (How many errors does the text contain? Has the most reliable edition been used as the base for the text? and so on) and intellectual property rights need to be adequately addressed before a scholar can use the text for serious work.
In this presentation however, I will concentrate on some technical issues that are related to some other areas of frustration to our scholar: Now that the data are available, there are a lot of other things that could be done with it, besides simple (or even more complex) searches. Texts could be analyzed, compared, annotated, corrected, interlinked, translated, connected with secondary sources, bibliographies, maps, dictionaries, still or moving images, audio content and any other imaginable digital resource. But alas, so far there is no way to do this with most of the data on the web so far. Although much more interactive than broadcasting media, the web as a medium still mainly provides content to the user, without involving the user in developing the content. The latter however, is the aim of the scholarly pursuit: Researching, publishing and digesting the research of others; in many areas also collaborating on smaller or larger projects. The Internet and the World Wide Web have the potential of enhancing these activities, but so far have largely failed to do so. The reason is for the most part that there are no applications to support this activity and a lack of standards that would allow such applications to talk to each other.
In an attempt to overcome these limitations, I have started a small research project, aimed at developing a System for Markup and Retrieval of Texts (SMART). Some information about this project is available at http://www.chibs.edu/~chris/smart. I will report on the progress of this project, and some underlying basic assumptions.
I.The Web today
The World Wide Web and the Internet in general form an unprecedented wealth of information that greatly advances many aspects of science and technology. One of its biggest strengths is also its most often mentioned weakness: The information is chaotic, unorganized and notoriously difficult to find.
A. A short example
As an example of what this means, consider the following example: Imagine a scholar of Chinese Literature, who would like to see what resources are available for the study of Lu Xun’s 魯迅works. He might go ahead and go to his favorite search-engine (there are now more than 200 general search engines for the whole web, not counting specialized engines for some specific domains) and type in what he is looking for.
Figure 1 shows what I got back when I made this experimental search. Due to the dynamic nature of the Internet, it is likely that the result will differ if someone else tries to repeat this little experiment shortly afterward. In almost no time, I was presented with the results of this search, which yielded a staggering 4600 documents containing the words Lu and Xun. Google (at www.google.com ) does a remarkable good job at analyzing the query and coming up with relevant results. As can be seen from the next line on the screenshot, the search term was recognized as belonging to the field of modern Chinese Literature
The first link leads to a website devoted
to the works of Lu Xun, introducing his main works in English. It also links to
some places where electronic copies of his work in Chinese can be downloaded.
The second page listed on the Google search result has the title Lu Xun
homepage, but not much more can be gleaned.
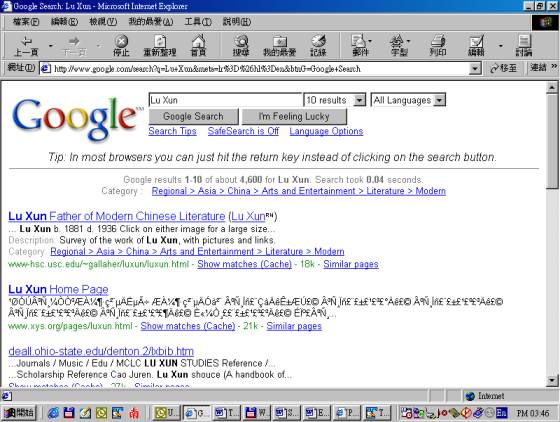
Figure 1 Results of a search for “Lu Xun” in the Internet Search Engine Google
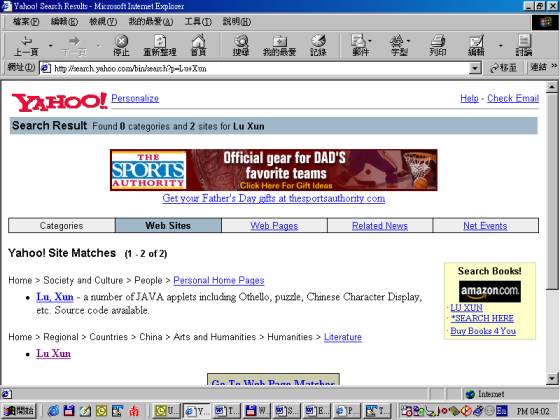
Figure 2 Results of a search for “Lu Xun” in the Internet Search Engine Yahoo.
Google does a good job at giving back relevant results, as can be seen by comparing the result of the search with Google to that of another search with the search engine Yahoo (at www.yahoo.com), where it takes much more effort to come to results of significance to the question at hand. Of course, I could continue to introduce other search engines and use other search terms (like Lu Hsün, 魯迅, 鲁迅 etc.), but this paper is not about search engines and research strategies, so I will not continue to elaborate this example.
B.Analysis
Now what observations can be made from this small example? It seems immediately clear that there is plenty of readily accessible information on Lu Xun on the Internet. The question remains however, how much our scholar of Chinese Literature is gaining from this. If we assume that he specializes in Lu Xun, most of the introductory material will be of little use to him, and he might even be author of some of the articles cited here. But of course, there is also primary material in the form of electronic transcripts of Lu Xun’s works available. The second link on the Google screenshot above in fact leads to a site with a pretty impressive collection of Lu Xun texts.
On the screen above, this could not be seen however, because the Chinese characters are garbled by the system, a phenomenon I am sure every Internet user of Chinese language resources is intimately familiar with. The material on this website is in simplified characters and if I switch the browser to display this, I will be able to read it without problems. They will however still be in simplified characters and obviously not transcribed from the original, which was written before the character reform. More problematic, there is no indication as to exactly which edition has been used, so it will be very difficult to see if there have been any errors in this transcription.
Now, having the electronic text surely is very nice, but our scholar certainly already has a number of editions of these works in his library, so if he just wants to read them, he certainly could just pick one off of the bookshelf. He could of course use the electronic text for looking up the usage of certain terms or phrases he can’t remember exactly. This usage is possible, but hindered considerably by the fact that no page references to a reference edition exists. The advantage of having the text in electronic form lies in being able to ask questions about the text, analyzing its word-usage, composition details and hundreds of other features that literary historians are interested in. Eventually, our scholar would also be interested in comparing Lu Xun’s work to some of his contemporaries or successors and use this to test some of his theories.
With the material that is accessible through the Internet this certainly is not impossible. It is however quite a daunting task and not one most scholars of literature would be able or willing to complete.
II.Remedies
There are of course various opinions on what can be done to rectify this situation and I will present some of them here. There are different problems and they need to be addressed at different levels. On the level of individual texts, we have the problem of verifying the transcribed text against the source edition. In doing this, we sometimes even would like to use different editions as sources and note the differences. Just to give a name to solutions to this class of problems, I will call them low level remedies. These will deal with issues like what syntax and semantics to use to express facts about the text and how to represent and store the text in the computer. There is also another class of remedy, that deals with the infrastructure that is available to organize these resources, I will call them high level remedies, since they build upon the lower level type.
A.Low level remedies
1.Encoding
Texts are stored as numbers in computers and every character to be displayed needs to have a number assigned. Chinese characters are used in a number of different regions and political domains in East Asia. Most of these have defined their own set of characters and assigned numbers to them, and this leads to great difficulties when operating across such boundaries, as is the case with the Internet today.
This problem has long been recognized and efforts began to standardize the character assignment worldwide. Two competing efforts started more than ten years ago, by an industry consortium and working groups of the International Standard Organisation (ISO).[1] Fortunately these efforts were synchronized and published as “The Unicode Standard 1.1” and ISO 10646-1:1993 in 1993. The most recently published version is Unicode 3.0[2], with the corresponding ISO version expected to be published shortly. For all practical purposes, these standards are identical today and can be used interchangeably. For brevity’s sake, I will henceforth refer only to Unicode which is meant to include ISO 10646 as well.
The Unicode standard now contains 27 484 Han characters. In the early stages, these characters where selected from existing national standards and identical characters were mapped to the same code points. Slightly different character forms were unified[3], as is outlined in the Unicode standard.[4] This unification was controversial in many cases, since it was applied across typographic traditions.[5] The unification was not applied if in one of the national standards two different code points existed for a character that otherwise would have been unified to one code point. This rule, the so-called source-separation rule was introduced to enable conversion without loss of information to and from existing standards. For users of Unicode, this has however very serious drawbacks. For a number of frequently used characters this resulted in two or more different code points for characters that should expected to be at the same code point, thus forming a great obstacle to search operations and analysis of Unicode text.[6]
Although not all problems with Unicode have been solved, it represents a big leap forward compared to the many encodings encountered on the Internet today With Chinese text however, there will always be the problem that some characters are not found in the standard character set and this problem does not go away with Unicode. The Unicode standard introduces so-called ideographic description[7] in version 3.0 to overcome this problem. This introduces some special characters to spell out the parts a complex character is composed of. It remains to be seen, if this can be applied in praxis, as there will certainly be some characters that cannot be expressed with this method.
Another widely used method is to encode a pointer to an outside reference collection of characters, as for example the KanjiBase[8] or the database of the Mojikyo Font Institute.[9] Within the field of Buddhist Studies, the latter approach seems to rapidly become a de-facto standard.[10]
2.Markup languages: SGML/XML
The need to express facts about the text in the computer in the computer file itself has been felt early on. The practice that evolved out of this need follows a long development in the print medium, where spaces, punctuation, page numbers, tables of context, indices, running headers and so on have all evolved over centuries and are still evolving. It is more closely modeled on the way editors communicated their needs to printers at the typesetting line, by inserting certain symbols for the desired size, typeface, font style and so on. This process is called markup and for that reason languages to express this are called “markup languages”. Most word processors use a markup language of their own, the details of which are a company secret kept hidden by the vendors producing them.
For interoperability between different programs and operating platforms and to protect the investment on a long-term basis, open standards for text encoding were devised. The most recent is XML[11], a standard developed by the World Wide Web Consortium[12], based on the much older ISO standard 8879 (SGML).[13] XML basically describes syntactical rules of a language, that can be used to describe what appears in a text. This meta-information is set apart from the text by enclosing it into angled brackets. The following could be used to identify a paragraph in XML, although XML says nothing about the semantics of the tags used: <p>This is a paragraph</p>
3.Markup semantics: TEI P3
Using SGML as the basic syntax, an international group of more than one hundred scholars from various fields of the Humanities formed the Text Encoding Initiative (TEI) and worked over more than seven years under the auspices of three learned societies, called to define some Guidelines for the Encoding of Electronic Texts[14], published in 1994. Today these guidelines are being implemented by a great variety of electronic text projects worldwide. These Guidelines define more than 400 different elements and give examples and guidance on how to and in which cases apply them to an electronic text. The work of TEI has been very influential to the definition of XML and today many projects working with TEI have switched from SGML as a base to XML, which is an easy transition in most cases. To continue the example above, in <p>This is a paragraph</p> TEI defines the meaning of the element p, its possible attributes and the places it can occur in a given text.
There are, of course, hundreds of other tag
sets and document type definitions (DTD) but TEI is uniquely suited for texts
prepared for academic research and teaching.
B.Higher level remedies
The three remedies from the previous section build on each other and enable a rich expression of the structure and contents of a text. They provide however no means for the user to interact with the text. For display, printing, searching and all other kinds of interaction, additional steps needs to be taken. Furthermore, individual texts need to be brought in context of other texts to form text corpora. In the terms used by Lawrence Lessig, code needs to be used to create architectures.[15] What kind of code we use to create what kind of architecture is completely our own decision. In the following sections, I will outline my current vision of such an architecture.
1.Flexible architecture to support
collaborative enhancing of rich texts
Here are some concrete requirements I currently see for such an architecture:
1. Direct support for the markup as recommended in the TEI guidelines.
2. Direct display of all Chinese characters and of other writing systems as well. Transparent support of the various encoding schemes used today in East Asia through Unicode.
3. No architectural distinction between local operation and operation through the Internet.
4. Support for the building of text-corpora that allows for index-based text-retrieval, with a provision for making use of the existing markup.
5. Support for the search for corresponding parts to the current division in the corpus.
6. Support for the interactive encoding of quotes and pointers to other locations of a text (hyperlinks) and the traversing of these links.
7. Support for the maintenance of databases of proper nouns, terminology etc.
8. Support for the alignment of multiple versions of a text (possibly in different languages)
9. Support for incremental edition and revision of the text. Changes will be tagged with an identification of the user and logged. They should be reversible individually.
10. Support for network based collaboration through a common view of the texts.
2.The notion of layered markup
Markup as defined by the TEI guidelines and generally used throughout the SGML/XML user communities tends to be monolithic. In most cases, all markup relevant to a text is inserted inline within the text.[16] In fact, this is one of the great advantages of this type of markup, since it allows easy maintenance of the markup without requiring specialized editing programs.
There are, however drawbacks to this approach. As I have argued elsewhere,[17] I think markup to a text can be usefully divided in structural markup, which basically captures the information implicit in the layout of a printed page and content markup, which deals with the actual content of the text. While the structural markup states facts about a text, content markup to a large degree consists of interpretation of the text. While most of this could be undisputable facts, it may not necessarily be agreed upon by all readers of the text. Furthermore, the markup fall under the purview of quite different fields. For example, markup introduced by a linguist vs. markup introduced by a literary critic.
The solution to this would be an architecture that allows layering of markup. Instead of adding all markup inline to the text, the text could have just the basic structural markup inline (which is required for navigation and addressing into the text) and have the content markup layered on top of it. Different views of a text could be constructed by selecting different layers of markup in the same way GIS[18] software allows users to select only the features of a map they are interested in. As in the architecture envisioned here, GIS also uses a common basic reference system (usually the outline of a country or a region) for the different layers. Technically, this solution could adopt the recent recommendations or candidate recommendations XPath[19] and XPointer[20] to express references of the layered fragments to the texts.
III.Towards a scholar’s workbench
To become truly useful to scholars, having the texts available through the architecture described above is not quite enough. Scholars need to use a wide range of references from historical documents and tables, to dictionaries and reference databases. Increasingly, there is also a wide range of digital images, audio- and video footage available. The concept of a scholar’s workbench would to allow the integration and interoperability of all these different resources. Since this cannot be done by one single project or one single institution, the only way I can see this happening is through the usage of existing open standards and the definition of new standards where necessary.
A.A short history of the SMART project
The System for Markup and Retrieval of Texts (SMART) was conceived to develop a prototype of such an architecture. Work began in early 1997 and has proceeded in three major stages. As is frequently the case, it turned out to be a winding path of trial and error, with many dead ends. Since progress relies heavily on the errors made, I will briefly recount three major development stages.
1.First Stage: An database driven
application with Web-frontend
The first presentation of a prototype of the SMART project was made at the third conference of the Electronic Buddhist Text Initiative (EBTI) in October of 1997.[21] At that time, I used the electronic version of the Korean Buddhist Tripitaka that had been published on CD-ROM the year before.[22] I converted the text to TEI compatible SGML format and fed it into a database. The database I used at that time was allegro-c,[23] a hierarchical database designed for use in libraries. What made this database attractive for this project was its impressive flexibility in constructing the search index from the records and its hierarchical structure, that made it easy to at least partly reflect the hierarchical structure inherent in the markup of SGML/XML texts.
While the prototype could successfully query the database and display the results over the Internet, and even allowed the user to set some display attributes, it turned out to be a maintenance nightmare. The index had to be defined in allegro-c’s own export language, the connection was made through a separate database server, that in turn served its data through a web server by way of some rather complicated CGI scripts. Changes were cumbersome to make and the prototype never became able to allow editing of the database through the Web, which was one of its design goals. Obviously, this was a dead end.
2.Second Stage: Implementation on top
of Microsoft Word
With new funding for this project provided by the German Research Council (DFG), I started to look for a way out of this dead end. In the meantime, I had become involved with the Chinese Buddhist Electronic Text Association[24] (CBETA), so I decided to use the texts produced by CBETA in XML format for the next prototype. Much time and effort went into the design of an index format[25] that would provide a layer of abstraction to access the texts.
As a concrete indicator of the concept a prototype retrieval engine has been built. This engine works on top of MS-Word. It accesses the files in Word format released by CBETA on their most recent CD-ROM[26]. Two versions have been used, one using two characters following the indexed characters, the other with four characters following the indexed character and two preceding characters, bringing the total length of the text entry to 7.
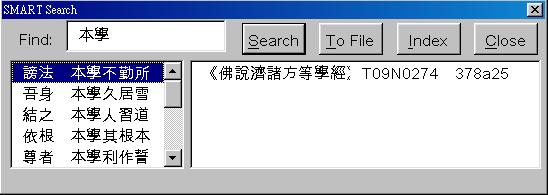

With this retrieval engine, any string of up to three (in the
first index) or up to five (in the second) index can be immediately accessed.
For longer strings, repeated lookups would have to be done, which slows down
the retrieval to a certain degree. Search behavior on Chinese Internet sites
suggests however, that most search terms used for retrieval are two or three
characters in length. The search term can either be entered in a dialog box or,
if the text is already open in Word, simply highlighted before invoking the
search engine.
In Figure 3, the search box of this prototype is shown. The characters 本學have been typed in the find box and the search button has been pressed. The list in the lower left gives strings that begin with the search term and show some context to the left and right. This list is available almost immediately. In the lower left is a list of locations of the string highlighted to the left. Doubleclicking on a location opens up the file on the desired location. The highlight in the left list can be moved up and down, thus providing a way to browse the index. Click on the “Index” button allows the selection of another index, in this case only the Taisho index with a text-entry length of three characters is available, although any index in the format outlined above could be used.
The button “To File” produces the following output in a new file:
Search term: 本學 Occurrences: 25
|
-2 |
-1 |
Index |
Title |
Location |
|
謗 |
法 |
本學不勤所 |
T09N0274, p378a25 |
|
|
吾 |
身 |
本學久居雪 |
T15N0606, p210a29 |
|
|
結 |
之 |
本學人習道 |
T04N0212, p736a20 |
|
|
依 |
根 |
本學其根本 |
T31N1598, p429b23 |
|
|
尊 |
者 |
本學利作誓 |
T28N1547, p416b09 |
|
|
學 |
如 |
本學善學無 |
T14N0573, p946b07 |
|
|
聖 |
實 |
本學地聽聞 |
T03N0160, p351b23 |
|
|
姓 |
子 |
本學大乘為 |
T12N0345, p162a16 |
|
|
言 |
我 |
本學婆羅門 |
T14N0458, p438b05 |
|
|
耶 |
二 |
本學師之所 |
T11N0310, p266c10 |
|
|
不 |
變 |
本學明了在 |
T12N0360, p266a27 |
|
|
菩 |
提 |
本學是勤修 |
T10N0279, p72c05 |
|
|
說 |
我 |
本學是法能 |
T16N0657, p199a15 |
|
|
畏 |
佛 |
本學時在佛 |
T09N0274, p377b18 |
|
|
如 |
吾 |
本學此三昧 |
T14N0425, p64a02 |
|
|
諸 |
佛 |
本學皆由精 |
T14N0481, p627b16 |
|
|
佛 |
子 |
本學真諦解 |
T10N0292, p653b29 |
|
|
眾 |
生 |
本學習世出 |
T13N0414, p815b06 |
|
|
聽 |
者 |
本學聲聞尋 |
T14N0459, p441c15 |
|
|
性 |
之 |
本學般若波 |
T08N0221, p100c17 |
|
|
此 |
字 |
本學通諸法 |
T12N0376, p887c22 |
|
|
時 |
人 |
本學道不值 |
T17N0767, p701a06 |
|
|
曰 |
汝 |
本學道二十 |
T12N0384, p1052c05 |
|
|
心 |
為 |
本學道人眾 |
T32N1670B, p708b23 |
|
|
其 |
佛 |
本學道時至 |
T14N0481, p627a17 |
|
|
為 |
四 |
本學道時設 |
T03N0186, p504b16 |
Again, this result is hyperlinked to the original text files, and clicking on the title will open the file at the specified position. Additionally, since this is an ordinary Word file, the table can be printed, pasted into other documents, or sorted according to different rows. For this purpose, characters preceding the search term have been put in their own cells, to facilitate their usage as sorting keys. It goes without saying that there are a lot of other possibilities to analyze such a file.
The advantage of building the workbench on top of MS Word is that this is for many scholars a familiar environment, so they do not need to learn a completely different application. Furthermore, it is easy to use the results in research papers and publications, if they are also edited with Word.
The downside is of course that any prospective user will first have to purchase a copy of Word, if he does not already own one. There is also a much greater limit of possible platforms: While every existing platform does have a web browser and therefore could potentially use the first prototype, with this prototype the audience is much more limited.
Apart from that, there are some technical problems. The layering of markup, which could be built on the fly from XML files, is very cumbersome if used on MS Word. The way the indexes have to be constructed to support access from Word also makes it impossible to dynamically update them. In short: Using MS Word was part of the problem, not of the solution.
3.Third Stage: Zope based
Web-Application
Looking for alternatives to the current
approach, I came across the Zope Object Publishing Environment (Zope).[27]
Zope is a platform to build dynamic Web-Applications, for the most part written
in the object-oriented programming language Python. It contains an object
database that stores objects in a tree-like hierarchy, and already had basic XML support built in when I 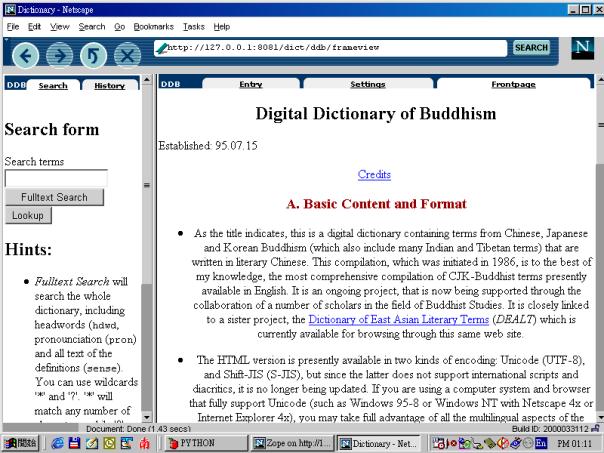 looked at it. It even contained a very flexible search engine, and
it was Open Source software available with source code free of charge.[28]
After some initial testing I was convinced that this was the platform I
looked at it. It even contained a very flexible search engine, and
it was Open Source software available with source code free of charge.[28]
After some initial testing I was convinced that this was the platform I  was looking for.
was looking for.
The first thing I developed with Zope in the context of the SMART project was a generic product for displaying and searching TEI texts.[29] I then proceeded to work with East Asian texts. I decided to use Charles Muller's Digital Dictionary of Buddhism[30] as the first test case, since this dictionaries uses Chinese, Japanese, Korean as well as transliterated Sanskrit and Tibetan and therefore poses quite some technical problems. While working on this, I was quickly reminded, how convenient it is to have the source code available: Some changes needed to be made to the indexing engine to allow for correct handling of Unicode UTF-8 characters. With the source code at hand, it was easy to make these changes and a problem was solved. This would have proved a major roadblock with closed-source software.
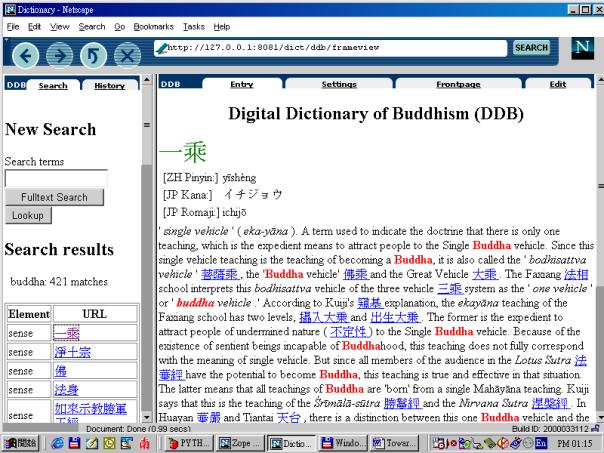
 Figure 4 shows the start
page of the dictionary in its current form, which is a very early prototype.
The screen is divided into two panels, with the left side panel showing the
front matter of the dictionary and the right hand side a search entry form.
Searches can be made as headword lookup or as full-text search in the dictionary entries. In this screen, the search
term “buddha” has been entered and a full-text search started. The resulting
screen is shown in Figure 5. The results are returned weighted by relevance,
entries most relevant to the search will be grouped first and the element
containing the match is shown. In Figure 5, the first entry of the result list
has been clicked to display the corresponding entry. The search term is marked
on the entry screen to allow easy location.
Figure 4 shows the start
page of the dictionary in its current form, which is a very early prototype.
The screen is divided into two panels, with the left side panel showing the
front matter of the dictionary and the right hand side a search entry form.
Searches can be made as headword lookup or as full-text search in the dictionary entries. In this screen, the search
term “buddha” has been entered and a full-text search started. The resulting
screen is shown in Figure 5. The results are returned weighted by relevance,
entries most relevant to the search will be grouped first and the element
containing the match is shown. In Figure 5, the first entry of the result list
has been clicked to display the corresponding entry. The search term is marked
on the entry screen to allow easy location.
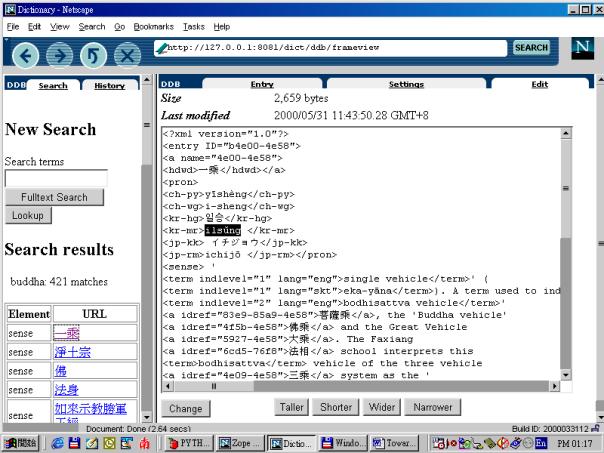
Below the headword are some lines, giving the reading in Chinese and Japanese. The display of these readings, as well as a number of other settings can be changed on the Settings screen (not shown). Figure 6 shows the XML source of the entry, which can be edited and saved over the web, the index will be updated accordingly.
 Zope already provides
excellent support for XML and a very powerful environment excellently suited for
the task at hand. The XML support is currently seeing a major overhaul, a first
prototype of XSLT[31]
transformations as well as DOM level 2[32]
is currently tested..
Zope already provides
excellent support for XML and a very powerful environment excellently suited for
the task at hand. The XML support is currently seeing a major overhaul, a first
prototype of XSLT[31]
transformations as well as DOM level 2[32]
is currently tested..
A major advantage is also the object-oriented implementation of Zope, which makes it easy to extend or replace functionality as needed.
IV.The significance of Open Source development
As has been shown, the SMART project went through two implementations on proprietary, closed-source software and ran into insurmountable problems, but development was swift and very successful on open source software. This is no accident but a direct consequence of the different discourse models on which these development strategies are based. Since this is not only relevant to this project in so far as it provides a development platform, but also as an example of how to successfully implement a cooperation model that allows distributed collaboration, it is worth further investigation.
A.Open Source as a discourse model
Open Source development was the first and natural mode of software development in a time when software was essentially built around specific hardware.[33] The aim is to make the best possible software available to everybody who needs it. To achieve this, the software that is exchanged, is exchanged as source code because only this enables everybody to learn from how any given project was implemented, to improve the way it was done or to adapt it to new circumstances.
It has been noted frequently that the open discourse derived from this activity is very similar to the discourse of science.[34] Both aim at enhancing knowledge and depend on the free flow of information. Progress is hindered if this free flow is not taking place. Open source software projects are thriving on this free flow of ideas and solutions.
Eric S. Raymond, who was instrumental in bringing the open source development model to the attention of non-programmers,[35] also made an anthropological analysis of some of the unspoken agreements surrounding this development model.[36] Taken as a whole, the way the discourse on the development of a project is conducted, comes surprisingly close to an “ideal communication” or “ideal discourse” based on “communicative rationality” as discussed, for example by Jürgen Habermas and Karl-Otto Apel.[37] This can be seen for example by looking at the archive of, for example the mailing list devoted to the development of Zope.[38] Most, if not all members make a constant effort to stay focused on the topic, provide relevant contributions and try to let the whole project evolve into a yet unknown direction that is nevertheless a common goal.
B.Open Source as a supporting infrastructure
The scholar’s workbench in its current incarnation is based on open source software, but its aim is also to provide an infrastructure to enable a discourse similar to the discourse among open source developers, but in a different realm. Instead of improving and developing a software package, the aim is to cooperatively develop a corpus of richly marked up and interlinked textual resources and accompanying reference works. There is certainly a lot to be learned from software developers, but many aspects of this infrastructure are yet undetermined and need to be gradually developed in a discourse among interested individuals. We need to define the architecture that supports our dialog and guides it as it evolves. Such an architecture does not lie in the nature of the net, but has to be actively developed by the members of a (virtual) community. In good open source tradition, I started this project by scratching my own itch, but as it gains momentum, I hope others will join in to make it a better tool.
V.Conclusions
This paper looked at the current state of the web in respect to how it could be used by a fictive scholar of Chinese literature and found it very rich in content, but poor in supporting infrastructure/architecture. It then went to look at some remedies on a theoretical level to proceed to introduce a project that tries to use these foundations to actually implement a new architecture, the scholar’s workbench.
The SMART project has gone through three major transformations so far and eventually found that Open Source software development not only leads to superior products in the long run, because it encourages the exchange of information, but as a discourse model could also be applied to the development of the contents of the workbench. The challenge is now to come up with a way to adapt this strategy to the different conditions of scholars in the Humanities, who are the main target audience for this tool.
VI.Appendix
A.Table of character variants in Unicode
The following table list characters occurring in slightly different forms in Unicode, depending on the format of the non-Unicode source. Some of these characters should have been unified according to the Unicode unification rules, but another rule, the source separation rule, prevented this. The latest version of this table is also available in electronic form at http://www.chibs.edu.tw/~chris/smart/ .
For the sake of clarity, the table has been split in two parts: Table 1 contains characters that are nearly identical; Table 2 contains characters that are fairly similar and could be considered identical for all practical purposes. The table contains the characters in question and the Unicode code points. Additionally, Chinese readings in Hanyu Pinyin romanization have been added as a reference. The column labeled “Remarks” is used to distinguish the two types and might be used for additional information.
Table 1: Nearly identical characters in Unicode with different mapping from Big5 and JIS
Table 2: Fairly similar characters in Unicode with different mapping from Big5 and JIS
B.Example of language dependent differences
that are not reflected in the encoding
As indicated, the distinction for different national typographic traditions most conveniently is not made at the encoding level, but rather reserved for the markup level. This example shows the rendering of a character encoded with the same code point in four different regions.
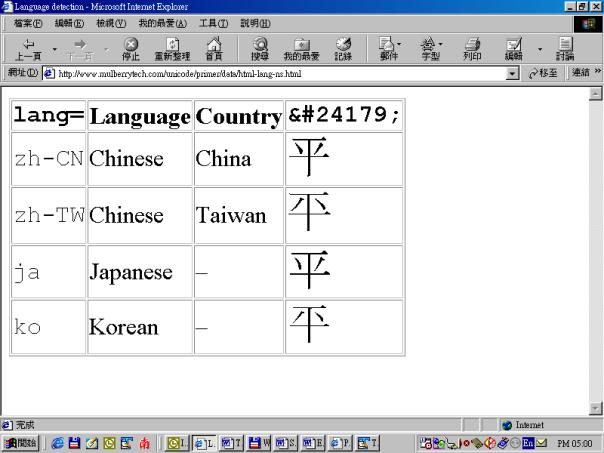
Figure 7 Different renderings can be triggered with the lang attribute in HTML
This example is adapted from the book Unicode. A primer by Tony Graham
VII.References
Apel,
Karl-Otto. Transformation der Philosophie, Frankfurt am Main: Suhrkamp
Verlag, 1973, 2 vols; partial trans. G. Adey and D.
Frisby, Towards a Transformation of Philosophy, London: Routledge &
Kegan Paul, 1980.
DiBona, Chris, Ockman, Sam and
Stone, Mark (eds.). Open Sources: Voices of the Open Source Revolution,
Sebastopol: O’Reilly & Associates, 1999. This book is also available online
at http://www.oreilly.com/catalog/opensources/book/toc.html.
DiBona, Chris, Ockman, Sam and
Stone, Mark. “Introduction”, in: Open Sources: Voices of the Open Source
Revolution, edited by Chris DiBona, Sam Ockman, and Mark Stone (Sebastopol:
O’Reilly & Associates, 1999), p. 1-17.
Goldfarb, Charles. F. The SGML
Handbook. Oxford: Clarendon, 1990.
Graham, Tony. UnicodeTM:
A Primer. Foster City: IDG Books Worldwide, 2000.
Habermas,
Jürgen. “Was heißt Universalpragmatik”, in K.-O. Apel (ed.) Sprachpragmatik
und Philosophie, Frankfurt am Main: Suhrkamp Verlag, 1976; trans. T. McCarthy as “What is Universal Pragmatics?”, in Communication
and the Evolution of Society, (London: Heinemann, 1979), 1- 68.
Lessig, Lawrence. Code and other
laws of cyberspace. New York: Basic Books, 1999.
Raymond, Eric S. “The Cathedral and
the Bazaar” (see http://www.tuxedo.org/~esr/writings/cathedral-bazaar/),
reprinted in Eric S. Raymond The Cathedral and the Bazaar: Musings on Linux
and Open Source by an Accidental Revolutionary, (Sebastopol: O’Reilly &
Associates, 1999), 27-78.
Raymond, Eric S. The Cathedral
and the Bazaar: Musings on Linux and Open Source by an Accidental Revolutionary,
Sebastopol: O’Reilly & Associates, 1999.
Raymond, Eric S. “Homesteading the
Noosphere” (see http://www.tuxedo.org/~esr/writings/homesteading/),
reprinted in Eric S. Raymond The Cathedral and the Bazaar: Musings on Linux
and Open Source by an Accidental Revolutionary, (Sebastopol: O’Reilly &
Associates, 1999), 79-135.
Raymond, Eric S. “A Brief History
of Hackerdom”, in: Open Sources: Voices of the Open Source Revolution,
edited by Chris DiBona, Sam Ockman, and Mark Stone (Sebastopol: O’Reilly &
Associates, 1999), 19-29.
Sperberg-McQueen, C. Michael and
Burnard, Lou (Eds.) Guidelines for Electronic Text Encoding and Interchange,
Chicago and Oxford, The Association for Computers and the Humanities (ACH), The
Association for Computational Linguistics (ACL) and The Association for
Literary and Linguistic Computing, 1994.
The Unicode Consortium. The
Unicode Standard Version 3.0, Reading, MA: Addison-Wesley, 2000.
Wittern, Christian. “The IRIZ
KanjiBase”, in: The Electronic Bodhidharma, Nr. 4, June 1995, p 58-62.
Wittern, Christian. “Minimal Markup
and More - Some Requirements for Public Texts”, conference presentation at the
3rd EBTI meeting April, 7th, 1996 in Taipei, Taiwan (An
abstract of this paper is available at http://www.gwdg.de/~cwitter/info/ebti96ho.htm.)
Wittern Christian. ”Review of the Tripitaka Koreana CD-ROM”,
http://www.gwdg.de/~cwitter/info/tkinfo.htm,
29.5.1996.
Wittern, Christian. „SMART project and the WWW Database of Chinese Buddhist Texts“, talk at the 4th EBTI meeting on October 23rd, 1997 in Kyoto, Japan.
Wittern, Christian. “Introduction to KanjiBase. A practical approach to the encoding of variant and rare characters in premodern Chinese texts”, in: Chinesisch und Computer, No. 10, Dezember 1997, p. 42-48.
Wittern, Christian. “Technical
note: SMART: Format of the Index Files” http://www.chibs.edu.tw/~chris/smart/smindex.htm
(January 10, 2000)
World Wide Web Consortium. Extensible
Markup Language (XML) 1.0. W3C Recommendation 10-February-1998. (http://www.w3.org/TR/1998/REC-xml-19980210)
World Wide Web Consortium. XSL Transformations (XSLT) Version 1.0 W3C
Recommendation 16 November 1999. (http://www.w3.org/TR/xslt)
World Wide Web Consortium. XML Path Language (XPath) Version 1.0 W3C Recommendation 16 November 1999. (http://www.w3.org/TR/xpath)
World
Wide Web Consortium. Document Object Model (DOM) Level
2 Specification Version 1.0 W3C Candidate Recommendation 10 May, 2000. (http://www.w3.org/TR/DOM-Level-2)
World Wide Web Consortium. XML Pointer Language (XPointer) Version 1.0 W3C Candidate Recommendation 7 June 2000. (http://www.w3.org/TR/WD-xptr)